
 In
In 
To alleviate system downtime and assure the high availableness of real-time servers, clusters are used. Clusters are groups of various servers that are mapped and worked together and participate in workload management. A cluster can contain number of nodes and other application servers. A node is basically a physical computer system with a different IP address that is running one or more application servers. It means that multiple servers are grouped together to achieve the same business and can be regarded as one computer. Logically associates many servers and clusters with different configurations in their organizational environments.
Clusters and Workload Management
While implementing the data center and the server management system for a huge enterprise that gets more than thousands of transactions per minute, the most important thing in that design is the “Clusters of Servers”. At least 2 servers with high and excellent quantity of memory must be clustered in a data center for every module or logic so that we should not face a situation of a deadlock resulting in all the messages getting cluttered in a queue. In the article, we will see some of the benefits of clusters and how they are formed and if clusters are not there, then what issues can arise for the enterprises.
The clusters do a very important job in solving many complex issues related to the software, hardware, network, memory, time, and location. You might be wondering sometimes, how clusters solve such important issues. The magic lies in the architecture in which the clusters are created and managed. The data centers mostly form the most important hardware location and mostly those are found centralized at one headquarters or at one place getting connected with various clients and various locations throughout. We can then fetch the data from and to servers. This setup of servers is common to solve the client-server technology, but in our enterprise where there is n-tier architecture with a client and various servers, starting from the technical files server, business logic files server, and the database servers, we must connect all these in a line to get the work done. Then to have the flow continuous without any stoppage, we must introduce clusters into server architecture.
Clustering or a server in a data center makes a server more robust and stronger to communicate with the databases, the messages in the queue, the clients, which can do the transactions in the real-time as well as in batch saving and utilizing time as needed. Clustering a server is the most important design pattern of a server that makes a server more powerful by creating high availability, a tough load balancer, and a directing agent of the messages to a particular node of a server checking how much data can a server-node manage and how much time will it take to process a functional data.
Clustering is an integrator of a data servers that divides the data into different nodes. This sort of design eases the hardware and its setup making it convenient for the hardware engineers to maintain it as there will be hardly any emergency required since if one node goes down the second node will take over and vice-versa. The software programmers accessing the server won’t face any issue such as down time or the server not responding which can go a long way to achieve the confidence of the team who is entirely dependent on working with these servers.
Types of Cluster Computing
Computer clusters can generally be categorized into three types:
- Highly available or fail-over
- Load balancing
- High-performance computing
1. Highly Available or Fail-over
High Availability (HA) clustering is a method used to reduce downtime and provide end-to-end service when certain system components fail. Highly Available clusters consist of number of (multiple) nodes that exchange the data and information through the grids and as a result, it is an efficient and robust way to ensure high system performance, availability, reliability, and scalability. The basic principle in this category of cluster is that if a case one node fails, then server applications and utilities can be made available to other nodes.
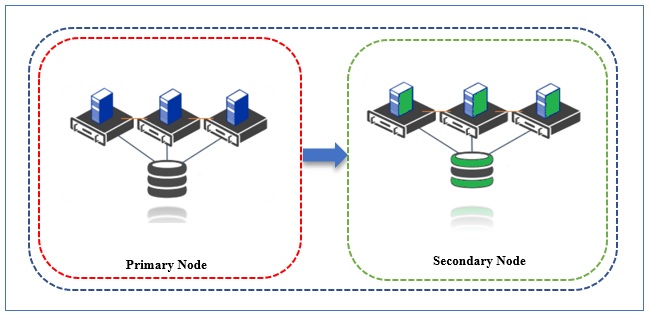
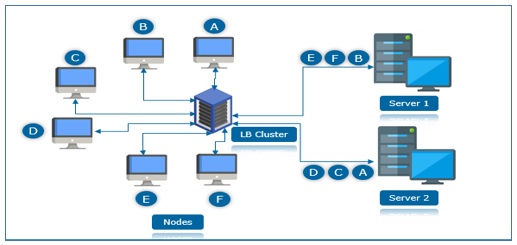
2. Load Balancing Cluster
Load Balancing Cluster allots all the incoming requests from various nodes towards the load balancer. By using certain advanced algorithm, all the requests and load is divided into multiple sub tunnels. In this Cluster model, all the server nodes are responsible for tracking orders, and if a node fails, then the requests are distributed amongst all the nodes available.
This typically works to manage the server workload so that it is evenly distributed among the multiple parent servers. The load balancer cluster monitors each server and divide the workload according to a predetermined formula or algorithm.
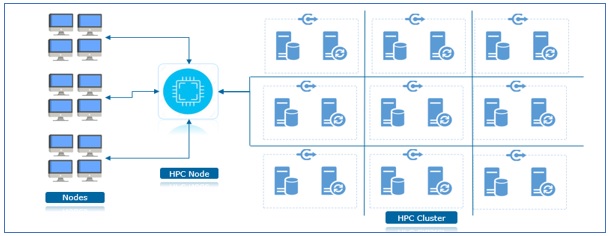
3. High-Performance Computing
A High-Performance computing cluster consists of number of computer server systems that are connected. Each server is called a node. The nodes in each cluster work in parallel with each other, boosting processing speed to deliver high performance computing.
High-Performance computing cluster plays an important role, in multiple industries and functions. In this type of cluster where thousands of computers servers use parallel processing to achieve higher computing power than could be achieved using just one of the computers in the cluster. A small cluster may use as few as four nodes, and a large cluster may have thousands of nodes. (A supercomputer has thousands of nodes, for example.) Regardless of how many nodes there are, multiple nodes use the power of parallel processing.
Advantages of Server Clustering
- Performance: Basically, measured as the response time, and turnaround time to perform several complex tasks with number of virtual machines at the same time. Clusters generate higher levels of performance.
- Availability: Clusters provide zero interrupted services by scheduling and distributing the complex work, or through shifting the application services to surviving nodes by way of a failover process.
- Scaling: Clustering servers is completely a scalable solution. You can add number of other resources to the cluster afterwards. Clusters have the ability to add capacity as needed and also flexible with the new technology configurations.
- Manageability: If a server in the cluster needs less maintenance, as there are number of advance applications which can triggered and continuously sent the statistics reports for the networked clusters. Clusters have the ability to be managed as a single system and restart and troubleshoot easily.
The server clustering concept ensures the round the clock availability to the online businesses and robotics environments even if there are some major issues going on with a server within the cluster. The server clustering is a successful solution implemented in many web hosting services, despite the fact that it has also some limitations. Also, when the clustering concept is applied to a project, the team gets free from continuously monitoring the availability of the servers and also, they get more time to think of more important solutions and manage the servers more efficiently. The additional tasks can be added in the servers like creating more parallel programming and scheduling of the jobs. The monitoring and the debugging of the cluster of servers more effectively since the fundamental things are sorted when we form the clusters.
The author is RPA Consultant at Atos India
Add new comment